2024

SoTeacher: Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
International Conference on Learning Representations (ICLR) 2024
How to train an ideal teacher for knowledge distillation? We call attention to the discrepancy between the current teacher training practice and an ideal teacher training objective dedicated to student learning, and study the theoretical and practical feasibility of student-oriented teacher training.
SoTeacher: Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
International Conference on Learning Representations (ICLR) 2024
How to train an ideal teacher for knowledge distillation? We call attention to the discrepancy between the current teacher training practice and an ideal teacher training objective dedicated to student learning, and study the theoretical and practical feasibility of student-oriented teacher training.

2023
Bridging Discrete and Backpropagation: Straight-Through and Beyond
Liyuan Liu, Chengyu Dong, Xiaodong Liu, Bin Yu, Jianfeng Gao
Neural Information Processing Systems (NeurIPS) 2023 Oral
Bridging Discrete and Backpropagation: Straight-Through and Beyond
Liyuan Liu, Chengyu Dong, Xiaodong Liu, Bin Yu, Jianfeng Gao
Neural Information Processing Systems (NeurIPS) 2023 Oral
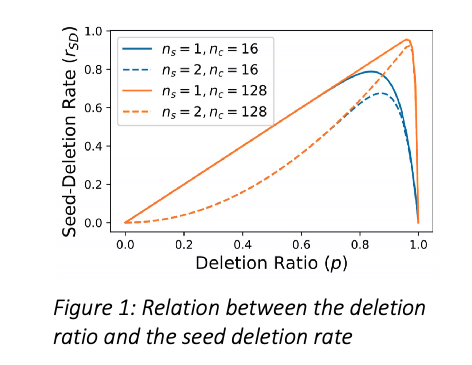
Debiasing Made State-of-the-art: Revisiting the Simple Seed-based Weak Supervision for Text Classification
Chengyu Dong, Zihan Wang, Jingbo Shang
Empirical Methods in Natural Language Processing (EMNLP) 2023
We show that simply masking the seed words can achieve state-of-the-art performance on seed-based weakly-supervised text classification
Debiasing Made State-of-the-art: Revisiting the Simple Seed-based Weak Supervision for Text Classification
Chengyu Dong, Zihan Wang, Jingbo Shang
Empirical Methods in Natural Language Processing (EMNLP) 2023
We show that simply masking the seed words can achieve state-of-the-art performance on seed-based weakly-supervised text classification
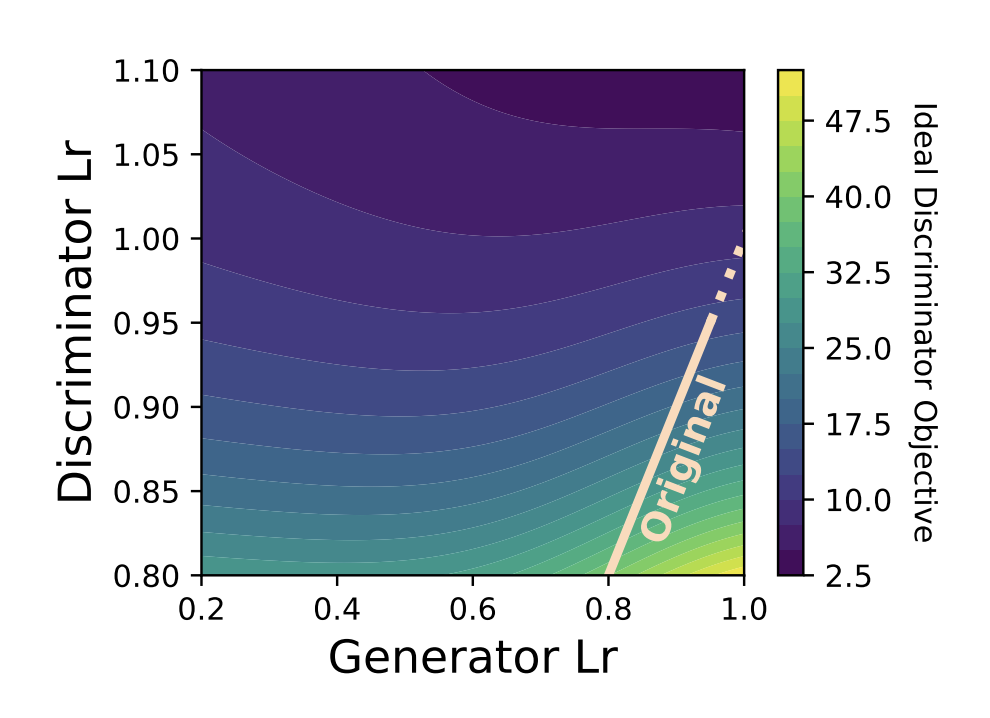
Understand and Modularize Generator Optimization in ELECTRA-style Pretraining
Chengyu Dong, Liyuan Liu, Hao Cheng, Jingbo Shang, Jianfeng Gao, Xiaodong Liu
International Conference on Machine Learning (ICML) 2023
We found that improper control of the generator optimization in ELECTRA-style pretraining is the main cause of the generator "overfitting" phenomenon, and proposed a simple method to fix it.
Understand and Modularize Generator Optimization in ELECTRA-style Pretraining
Chengyu Dong, Liyuan Liu, Hao Cheng, Jingbo Shang, Jianfeng Gao, Xiaodong Liu
International Conference on Machine Learning (ICML) 2023
We found that improper control of the generator optimization in ELECTRA-style pretraining is the main cause of the generator "overfitting" phenomenon, and proposed a simple method to fix it.
2022

Label Noise in Adversarial Training: A Novel Perspective to Study Robust Overfitting
Chengyu Dong, Liyuan Liu, Jingbo Shang
Neural Information Processing Systems (NeurIPS) 2022 Oral
We show that robust overfitting in adversarially robust deep learning is likely the result of the implicit label noise in adversarial training. Robust overfitting is thus the early stage of an epoch-wise double descent and is not a new phenomenon.
Label Noise in Adversarial Training: A Novel Perspective to Study Robust Overfitting
Chengyu Dong, Liyuan Liu, Jingbo Shang
Neural Information Processing Systems (NeurIPS) 2022 Oral
We show that robust overfitting in adversarially robust deep learning is likely the result of the implicit label noise in adversarial training. Robust overfitting is thus the early stage of an epoch-wise double descent and is not a new phenomenon.
