
I am a PhD student in Computer Science at UCSD.
I am interested in the principles (and theories, if possible) of learning efficiency, especially data efficiency, as well as principle-guided efficient learning algorithms in realistic applications. I believe learning efficiency defines intelligence.
Fun facts about me:
- My previous research focus was Physics and Astronomy, in particular Solar System Dynamics, that means the motion of any objects outside Earth and within our solar system (Yes, you are right! The three-body problem!)
- Football (or soccer?) is my life. I play and watch games every week, rain or shine. DM me if you want to watch or play together! Football forever ⚽!
- I love drama. I read (and hopefully also write in the near future) drama scripts. I also acted in stage plays. My favourite playwright is Harold Pinter.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 University of California, San DiegoComputer Science and Engineering
University of California, San DiegoComputer Science and Engineering
Ph.D. StudentSep. 2021 - present
Experience
-
 NvidiaResearch InternJune. 2024 - present
NvidiaResearch InternJune. 2024 - present -
 Google DeepMindResearch InternJune. 2023 - Nov. 2023
Google DeepMindResearch InternJune. 2023 - Nov. 2023 -
 Microsoft ResearchResearch InternJune. 2022 - June. 2023
Microsoft ResearchResearch InternJune. 2022 - June. 2023
Selected Publications (view all )

SoTeacher: Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
International Conference on Learning Representations (ICLR) 2024
How to train an ideal teacher for knowledge distillation? We call attention to the discrepancy between the current teacher training practice and an ideal teacher training objective dedicated to student learning, and study the theoretical and practical feasibility of student-oriented teacher training.
SoTeacher: Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
International Conference on Learning Representations (ICLR) 2024
How to train an ideal teacher for knowledge distillation? We call attention to the discrepancy between the current teacher training practice and an ideal teacher training objective dedicated to student learning, and study the theoretical and practical feasibility of student-oriented teacher training.

Bridging Discrete and Backpropagation: Straight-Through and Beyond
Liyuan Liu, Chengyu Dong, Xiaodong Liu, Bin Yu, Jianfeng Gao
Neural Information Processing Systems (NeurIPS) 2023 Oral
Bridging Discrete and Backpropagation: Straight-Through and Beyond
Liyuan Liu, Chengyu Dong, Xiaodong Liu, Bin Yu, Jianfeng Gao
Neural Information Processing Systems (NeurIPS) 2023 Oral
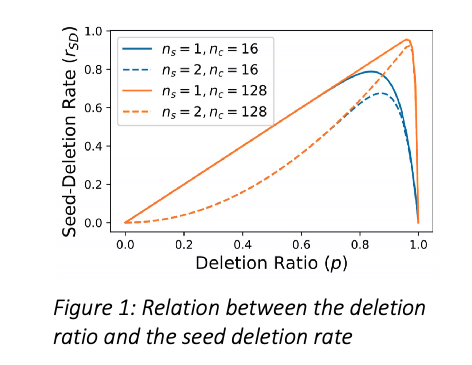
Debiasing Made State-of-the-art: Revisiting the Simple Seed-based Weak Supervision for Text Classification
Chengyu Dong, Zihan Wang, Jingbo Shang
Empirical Methods in Natural Language Processing (EMNLP) 2023
We show that simply masking the seed words can achieve state-of-the-art performance on seed-based weakly-supervised text classification
Debiasing Made State-of-the-art: Revisiting the Simple Seed-based Weak Supervision for Text Classification
Chengyu Dong, Zihan Wang, Jingbo Shang
Empirical Methods in Natural Language Processing (EMNLP) 2023
We show that simply masking the seed words can achieve state-of-the-art performance on seed-based weakly-supervised text classification
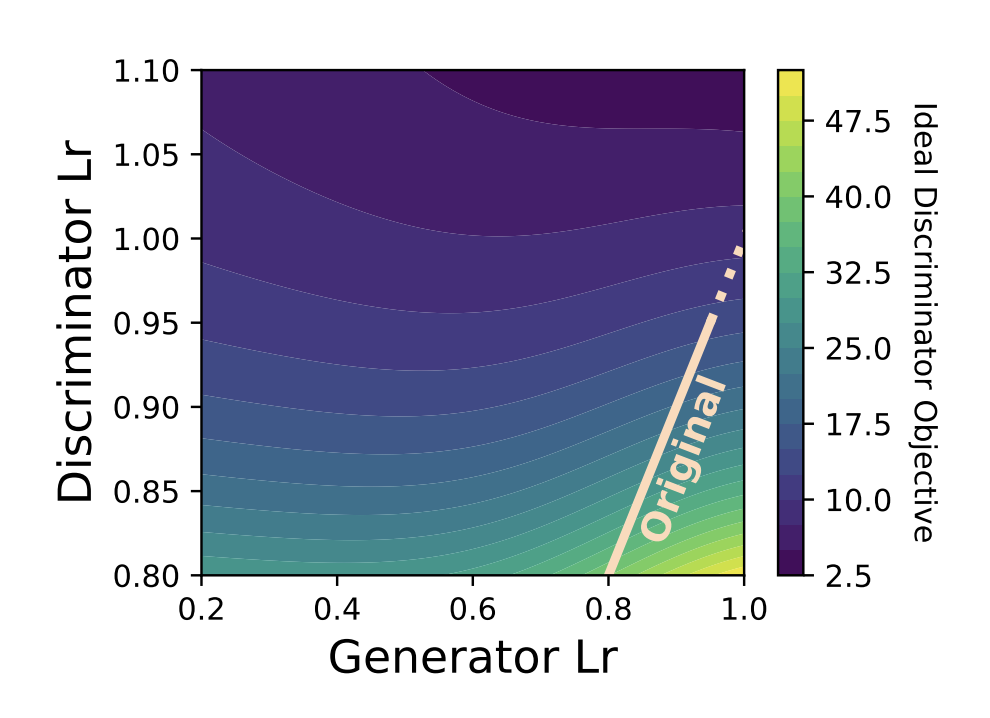
Understand and Modularize Generator Optimization in ELECTRA-style Pretraining
Chengyu Dong, Liyuan Liu, Hao Cheng, Jingbo Shang, Jianfeng Gao, Xiaodong Liu
International Conference on Machine Learning (ICML) 2023
We found that improper control of the generator optimization in ELECTRA-style pretraining is the main cause of the generator "overfitting" phenomenon, and proposed a simple method to fix it.
Understand and Modularize Generator Optimization in ELECTRA-style Pretraining
Chengyu Dong, Liyuan Liu, Hao Cheng, Jingbo Shang, Jianfeng Gao, Xiaodong Liu
International Conference on Machine Learning (ICML) 2023
We found that improper control of the generator optimization in ELECTRA-style pretraining is the main cause of the generator "overfitting" phenomenon, and proposed a simple method to fix it.

Label Noise in Adversarial Training: A Novel Perspective to Study Robust Overfitting
Chengyu Dong, Liyuan Liu, Jingbo Shang
Neural Information Processing Systems (NeurIPS) 2022 Oral
We show that robust overfitting in adversarially robust deep learning is likely the result of the implicit label noise in adversarial training. Robust overfitting is thus the early stage of an epoch-wise double descent and is not a new phenomenon.
Label Noise in Adversarial Training: A Novel Perspective to Study Robust Overfitting
Chengyu Dong, Liyuan Liu, Jingbo Shang
Neural Information Processing Systems (NeurIPS) 2022 Oral
We show that robust overfitting in adversarially robust deep learning is likely the result of the implicit label noise in adversarial training. Robust overfitting is thus the early stage of an epoch-wise double descent and is not a new phenomenon.
